
|
|
| Informatik Abt. I | Pagination -- Conclusions |
|
|
|
| Informatik Abt. I | Pagination -- Conclusions |
In this thesis the pagination problem of complex documents has been discussed. The pagination problem is to find a good distribution of a document's contents onto pages. Complex documents not only contain text, but also floating objects like figures, tables, or footnotes. Although this problem need not occur when documents are read through a computer screen, it is still important to be able to find good paginations. The reason is that humans read more efficiently from paper than from computer screens and consequently many people prefer to print a document before they read it.
Reading efficiency is influenced by many factors. Not paying attention to one of these factors may prevent efficient reading. Only if all factors are considered, a document may be read efficiently. The pagination quality is one of these factors. Although it is difficult to quantify pagination quality, we have introduced two new measures
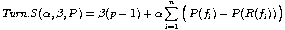
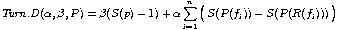
The idea with these measures is simple. They account for the number of page turns necessary to read the whole document. Documents printed on double-sided pages need page turns only (1) if a user has finished reading a page spread or (2) if a figure is placed on a different page spread than its reference. The lower the number of necessary page turns is, the better is the pagination.
Additional weights alpha and beta allow to adjust the measures to specific needs. For a conference paper it may be important to remain below a given number of pages, thus a high weight beta in our measures minimizes the number of pages. In a users manual it may be more important to have all figures placed on the same page with their references. Choosing alpha very high optimizes the page differences between figures and their references.
But there are other aspects of pagination quality, too. Widows and orphans must be avoided, facing pages must be balanced, other constraints have to be satisfied.
Today's systems use quite simple pagination algorithms. LaTeX uses a first-fit algorithm and the postprocessor of TROFF output by Kernighan and Van Wyk [KW89] has a fundamentally greedy behavior, too. These algorithms do not consider the number of page turns, but try to satisfy other restrictions. The advantages of the first-fit approach, especially of Kernighan's and Van Wyk's program are:
Unfortunately the paginations produced by simple pagination algorithms are not optimal. We have studied the pagination quality of online algorithms. Online algorithms are simple algorithms that have to operate without lookahead. The pagination algorithm of TeX and LaTeX, for example, belongs to this class. We have studied different document models where the complexity of the model is defined by two dimensions. One dimension is about the complexity of the input line boxes (are they stretch-/shrinkable or not), the other about the page classes.
| page classes | |||
|---|---|---|---|
| all-available | two-regions | ||
| input lines |
fixed heights, no stretchability or shrinkability |
optimal | not competitive |
|
fixed heights with stretchability and shrinkability |
not competitive | ||
In the restricted model where line boxes have a fixed height and cannot stretch or shrink, and pages are of the all-available page class, online algorithms produce optimal results. But if either the line boxes may stretch or shrink, or pages have to be of the two-regions page class, then no online algorithm is competitive. This means that the competitive ratio:
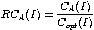
is not bound by any constant c. In this formula, CA(I) denotes the cost (i.e. quality) of an online algorithm A's pagination of input I. The cost of the optimal pagination is Copt(I). In other words, the results of online algorithms may be arbitrarily bad. This holds for all natural measures of quality.
Consequently it is the user's responsibility to produce a good pagination. Therefore, users often have to move floating objects around the input file or even change the contents a little, until the pagination algorithm produces a satisfactory pagination. The postprocessor of TROFF output from Kernighan and Van Wyk [KW89] is an example of this concept.
Another cause for not having better pagination programs may stem from the work of Plass [Pla81]. He proved that the complexity of finding optimal paginations depends on how optimality is defined. Some measures of quality like Quad or the zero-one badness function lead to an NP-complete pagination problem. This means that computer scientists have not found any efficient algorithm to solve such a problem yet. It is assumed that no efficient algorithms exist, but this has not been proved either. However, Plass has also shown that some measures of quality may be optimized in polynomial time by algorithms based on the dynamic programming approach.
We have proved that Turn.S and Turn.D are measures that satisfy the principle of optimality. Therefore, it is possible to optimize them with a dynamic programming algorithm, too. To cope with documents also containing footnotes, these measures have to be extended as follows
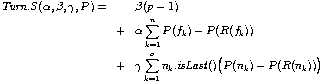
Unlike figures, footnotes consist of several line boxes and they may be split between pages. The number of page turns necessary to read a footnote completely, depends only on the page difference between the reference and the last line box of the footnote. Again, a weight gamma allows to adjust the measure to different needs.
Fortunately, the principle of optimality holds for the extended measures, too. Hence optimizing the measures may be done with an algorithm based on dynamic programming. The time complexity of the algorithm is in O(mno) with m being the number of line boxes, n being the number of figures, and o being the number of footnote line boxes. Moreover, a practical implementation also needs to have low running times. To minimize the running time we have developed:
We do not foresee that automated pagination programs, even when optimizing, produce acceptable paginations for all documents. Difficult cases, for example when figures should be compared, will always require human intervention. In general, this intervention is to relax some constraints (locally) or to specify additional constraints. In our implementation of XFormatter we provide two methods of interaction.
The constraint that pages have to be exactly filled may be relaxed. Users may allow pages to contain some white space at the bottom. If pages need not be exactly filled, the pagination algorithm has more choices and it is easier to place the floating objects on the same page as their references. The user may relax the constraint locally, i.e. only some pages are allowed to be "under-full", or globally by allowing all pages to be "under-full".
In the double-sided pages setting, however, facing pages must be balanced. Therefore it is useless to allow the left-hand page to remain only 90% filled, while the right-hand page must be exactly filled and must match the height of the left-hand page.
XFormatter searches a pagination that satisfies all these constraints and that needs a minimal number of page turns to read.
There are other methods of interaction, too. For example, users may want to place a figure only on a right-hand page --- for whatever reason. Or users may be interested to place a figure only on a specific page, say page 21. The algorithm allows to find an optimal pagination that must also satisfy these kinds of constraints, although we have not implemented it in XFormatter.
Paginating some real-world documents with XFormatter has produced encouraging results. The computed paginations are as good as paginations manually optimized by humans. This means that our measures of quality seem to come close to the human notion of pagination quality. Only sometimes it was necessary to further improve a pagination by specifying some additional constraints.
The experiments have also shown that it is important to distinguish between paginating for single-sided pages and paginating for double-sided pages. Each case has its own optimal solution.
In our examples, reducing the minimum fill level of all pages to 90% usually enabled the algorithm to significantly improve the pagination quality. Especially when double-sided pages were available, almost all floating objects could be placed on the same page spread. Usually not more than one extra page was needed to achieve these results.
Although the time complexity of the algorithm is optimal, running times remain high because of the usually large problem size. As expected, the running time increases if pages need to be less full, or if double-sided pages are available. Our results have shown that our pruning technique works very well. The running time was lowered by about 60%.
The same speed-up could be gained when VBoxes were used to compress the footnote stream. But this is only possible if footnotes are rather short. If footnotes are longer, then the compression rate gets smaller (a smaller percentage of lines may be grouped) and the running time cannot decrease so much.
Practically, the running time has never been more than one minute. Although this cannot be called true WYSIWYG, it still allows interactive use and saves a lot of time.
It would be interesting to know if it is sufficient to provide only the two kinds of additional constraints implemented in XFormatter or if other kinds of constraints are necessary, too. We think that for most documents it is sufficient to allow some pages to be "under-full" and to be able to specify some same/different page/spread constraints. But we have not taken a closer look at many documents. A further study could examine many documents to check if other constraints were necessary, and for which kind of document they may be necessary.
Often the pagination of documents is not done by computer scientists but by people with other background knowledge. Therefore, the user interface of a pagination program has to be simple enough. Right now, users may only add additional constraints. A user friendly system has to be able to display all constraints and to edit them easily, too.
To avoid that the algorithm cannot find any pagination that satisfies all constraints, a program should support its users. It may, for example, recognize inconsistencies or contradictions in the specified constraints and suggest how to remove them. But as it is hard for humans to understand the combination of many constraints, it is better to use them only seldom and not too many at the same time.
So far XFormatter does not distinguish between figures and tables. Both are integrated into one stream, which we have called figure stream. Hence we restrict a table i, cited between figures j and k to be placed between these figures. The style guides also allow the table to be placed before or after these figures, as long as all figures are placed in their order of citations and all tables are placed in their order of citations. This may improve a pagination's quality. In principle our approach may be extended to cope with more streams. This extension would result in a large increase of the search space. As adding the footnote stream has increased the search space from two dimensions to three dimensions, adding another stream increases the dimension of the search space by one. This would also result in an increase of running time. It has to be checked if the improvement in pagination quality is worth the speed decrease.
Right now only pages of the two- or three-regions page class are allowed. To also have multi-column pages, the pagination algorithm has to be extended, too. As the function that checks if some material may be placed on the same page is called very often, also considering two columns will slow down the pagination process.
To regularly use XFormatter it must be able to cope with lines containing more than simple text. Combining the pagination algorithm introduced in this thesis with Groves and Brailford's dlink system [GB93] might give a formatting system that allows more complex boxes than words in lines, and that would produce optimal paginations.
Another interesting area of research is the investigation of agent based pagination algorithms. The idea is that there are agents (processes) that are responsible for some part of the pagination, say one page or one page spread. A simple first-fit algorithm initially assigns some material of the input streams to each agent (page). Then the agents start to improve the initial pagination by trading with their neighbor agents (pages). One agent might want to get rid of the last line boxes on its page and offers them to the following page (agent).
It may be investigated if there is a simple set of trading rules that guarantee to achieve some specified quality in some specified time. It has to be guaranteed that there are no infinite loops where some agents move the same material forward and back again. Each agent may be controlled by some parameters and these parameters may allow users to control the pagination process.
The advantage of this approach is that it allows to easily exploit multi-processor computers to speed up the pagination task. Although XFormatter is quite fast, it takes some time to paginate a larger document. In a batch formatter this is tolerable, but in interactive systems response times have to be minimized.
© Universität Bonn, Informatik Abt. I - webmaster - Letzte Änderung: Tue Oct 16 16:28:05 2001