|
|
| Informatik Abt. I | Introduction to the Pagination Problem |
|
|
|
| Informatik Abt. I | Introduction to the Pagination Problem |
This thesis discusses the pagination problem of complex documents. In contrast to simple texts as novels, complex documents contain text, figures, tables, displayed equations, and footnotes. Examples of such documents are scientific reports, books, conference articles or manuals. The pagination problem is to find an answer to the question "how to distribute the document's contents nicely on pages?" The answer to this question depends on the following aspects:
Therefore there is not the pagination problem, but there is a set of pagination problems. Distributing a newspaper's contents on pages is completely different from distributing the contents of a scientific textbook on pages. Not only the document contents are different (many rather short articles in a newspaper vs. one long text in the book), but also the pages (large paper with many columns for a newspaper vs. smaller paper with one column for the book) are different. While the articles in a newspaper need not be presented in a strict sequential order, all chapters or sections in a textbook must be presented in one sequential order.
In this thesis we study the pagination of books and similar documents which are intended to be presented sequentially and which are printed on pages much less complex than newspaper pages. There is a strict order in the main text of the document which is only interrupted by figures, tables, or footnotes. These are referred (or also called cited or referenced) from some position in the main text, but usually they are not placed at exactly this position.
It is said that these objects may float over the text because they may be placed in various relations to the text or to each other. To read and understand a document it is necessary to look at figures in relation to some lines of text. A reader who encounters a reference to a figure often wants to look at the figure immediately. For that reason, a good pagination has placed the figure close to the reference, at best on the same page.
In many documents a reader not only wants to look at a figure immediately, but has to do so. Otherwise efficiently reading the document may be impossible. In scientific texts or manuals, for example, figures are inserted to explain some (otherwise difficult) text. If the figure is not available when a reader reads the difficult text, she or he might not understand the text. Therefore the reader has to search for the figure, which is annoying and clearly decreases reading efficiency. Reading efficiency is high if a reader may quickly understand the document's contents.
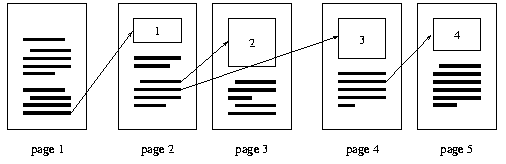
Figure 1 shows a bad pagination. The rectangles with numbers in them represent figures and an arrow points from the line that contains the reference (to a figure) to the referred figure. The lines in this example have different heights, only to make it easier to recognize the paragraphs. When the reader reads the first page, she or he reads about the first figure. But before the reader sees the figure, it is necessary to turn a page. When the reader reads about figure 2 she or he has to look ahead at the next page. As this example is printed like a book, pages two and three face each other at one page spread (also called opening). For that reason it is not so bad that figure 2 is not placed on the same page as its reference.
Now imagine that figure 3 illustrates a question. The answer to this question is presented in figure 4. The first problem with the pagination shown in Figure 1 is that the reader cannot look at figure 3 when she or he reads about the question. An extra page turn interrupts reading and understanding the question. If the reader turns to the next page spread, she or he not only sees the figure about the question, but also the answer is immediately visible in figure 4. In an educational text the author would probably prefer that figures 3 and 4 are not placed on the same page spread.
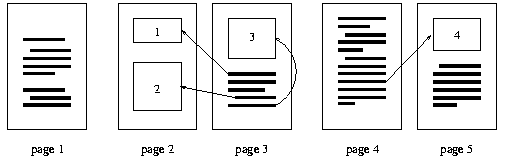
Figure 2 shows a different pagination of the same input. Here the last line of page one has moved to the second page spread, leaving page one a little "under-full". The second page spread contains all figures that are cited from the text on the second page spread. A reader who reads about the question can immediately look at figure 3 and understand the question. To have a look at the answer, the reader has to turn to the next page first.
Today more and more documents are produced with computers. It begins with the author who prepares a manuscript electronically instead of using a typewriter and paper. The manuscript may be distributed either electronically or in printed form. At the other end a reader may see a document printed on paper, or may look at it through a computer screen.
On computer screens the pagination problem need not occur. A page may be almost infinitely high. The user sees only a part of it, presented in a window where the user may scroll up or down. Scrolling is not limited to full pages (as is turning a page in a book), but a user may also scroll only some lines up or down. In this window environment no figure needs to float. It may always be placed at the desired position in the text. Moreover, a document may also be presented in two windows, one which contains the main text, and another which contains the figures. Both windows may be displayed next to each other on the screen. So why does the pagination problem still need a good solution?
The reason is that reading from paper is more efficient than reading from computer screens. Hansen and Haas studied the influence of several factors on the behavior of users reading with computers. One of the factors is the page size. Users have to scroll more often if the page size (i.e. window size) is too small. This takes time and interferes with concentration. Another factor is the legibility of the text, that is the ease with which letters and words may be recognized. As the resolution of computer screens is lower than the resolution of good printing engines, printed letters and words are easier to recognize.
Hansen and Haas also did some experiments to compare reading from computer screens with reading from paper. Some students had to perform some reading and understanding tasks. One group used computers, the other used paper. The following interviews showed that users especially had difficulties to get a sense of text while reading from computer. The sense of text was defined by Hansen and Haas as follows
By this we mean the feeling a user may have that he or she has a good grasp of the structural and semantic arrangement of the text --- the absolute and relative location of each topic and the amount of space devoted to each. Good sense of text is invaluable to a reader in finding parts of a text, following the thread of an argument, and getting the gist of the material.
These difficulties particularly arise when
One of the reasons for the problem of getting a sense of text stems from the fact that readers can recall the position of text on paper pages. This belongs to the well known technique of mnemonics called method of loci [SR94]. This technique is to symbolically place different items which are to be remembered in familiar environment locations. It supposedly was originated by a Greek poet named Simonides. It is said that Simonides attended a large dinner and after he had gone outside, the building collapsed. All other guests died and furthermore could not be identified, because the heavy stones caused too much destruction. However, Simonides was able to identify the bodies because he remembered the location where a person had sat.
This means that readers not only remember what they have read, but also where ("this Lemma was printed on a right-hand page right below a figure"). Moreover, remembering the location and arrangement of text simplifies remembering the topics read. The experiments of Hansen and Haas showed that the ability to remember the location (i.e. page and line) of specific items is higher for printed text. They conclude that "Every experiment showed that paper was superior for reading to any computer condition ..."[HH88].
Repeating these experiments in some years (when more and more people get familiar with using computers to read) may produce different results. But today there still is a need to have a printed representation of a document, especially for longer documents with difficult contents which must be critically read.
Another very obvious aspect that shows the need of printed documents may be seen in many book stores. There are plenty of books which describe the use of modern PC software. Most modern programs also contain an online documentation which a user may read or browse with the computer. These books contain almost the same information as the online documentation. Why are these books bought if reading from a computer screen would be as efficient as reading from paper?
Plass [Pla81] studied optimal pagination techniques during the development of TeX in 1981. He extended TeX's approach to break paragraphs into lines by dynamic programming, to breaking lines and figures into pages. A badness function defines the quality of a pagination. Plass showed that the choice of a badness function influences the complexity of an optimizing pagination algorithm. Some badness functions lead to an NP-complete pagination problem, while others allow to find an optimal pagination in polynomial time. His implementation dealt with documents that were only allowed to contain text and figures, but no footnotes. However, this implementation did not make its way into TeX, which uses a simple first-fit pagination algorithm.
Asher [Ash90] built a new system Type&Set based on TeX as the formatting engine in 1988. Type&Set operates in two passes. First, the text lines, figures and footnote lines are reconstructed from TeX's output file. Then, an optimizing pagination routine pastes the reconstructed material into pages. The measure to be optimized, although not explicitly presented, seems to mainly reflect page justification and balancing. Figure placement seemed to be only a secondary concern. It is also stated, that figures are allowed to appear one page after their citation. So probably Type&Set does not take full advantage of the availability of double-sided pages, where figures may be placed one page before their citation, too.
In 1989 Kernighan and Van Wyk [KW89] developed a page makeup program which postprocesses TROFF output. To supply the page makeup program with the necessary information, a special macro package is needed, too. The pagination algorithm has a fundamentally greedy behavior because Kernighan and Van Wyk wanted the pagination routine to be as simple and efficient as possible. Accordingly, they do not allow facing pages to run one line shorter or longer even if the page spread would be balanced. It also is not guaranteed that each footnote stays on the same page as its citation. On the other hand the postprocessor avoids widows and orphans, and also justifies all pages to the same height.
The strong point of their approach is that as long as a prefix of the document does not change, the pagination of that prefix does not change either. In other words, the first pages remain the same if only the final part of the document changes. A user may therefore sequentially proceed through the document to manually improve the placement of figures.
The block model introduced by Kernighan and Van Wyk has been extended and used by Evans [Eva90] and Groves [GB93]. In his parallel text formatter PARTEXT Evans formats the paragraphs of a document in parallel, i.e. all paragraphs are broken into lines in parallel. Afterwards the resulting blocks are placed on pages. As the focus of Evans's work has been to study parallelism in document formatting, only a simple pagination algorithm was used.
The separation of line breaking and pagination of a document was studied closer by Groves. He compared producing programs by compiling and linking with formatting a document by line breaking and paginating. Object code produced by different compilers may be linked together because the object code holds some properties. Groves studied the properties that a block (as a result of breaking a paragraph into lines) needs to hold, to allow a successful pagination of the document. Problems arise because of cross-references or the numbering of some components during the production of pages. In this work the focus is not on optimally placing floating objects either.
The automated pagination of newspapers was studied by Lagus [Lag95]. This pagination problem is different because the objects to be paginated vary in size and shape. There also is no strict sequential order to be maintained by the pagination algorithm. Other restrictions characterizing newspaper pagination are:
Therefore the newspaper pagination task may either be (1) to put all material into the newspaper and minimize space usage, or (2) to fill the given pages with relevant material from a large collection of material. Lagus studied the application of simulated annealing algorithms to task one.
There is a general agreement that documents should be efficiently readable. But it is not clear how to quantify the fact that a pagination is good (i.e. a document is efficiently readable) because quality depends on many subtle factors. Moreover, print quality also depends on people's expectations and training in reading.
In today's document formatters users have to specify preferences and constraints on the placement of figures. A user may specify constraints for all figures, but only for each figure itself. To our knowledge no system allows to specify constraints for two figures, for example, two figures that must be placed on different pages.
Today's systems also fail to take full advantage of double-sided pages. Books are printed alternately on right-hand pages and left-hand pages. In this case floating objects are allowed to float on a page before their references if the reference appears on the same page spread. Otherwise floating object may only float to following pages.
To get the desired pagination users are forced to manually intervene in the pagination task. They insert explicit page breaking commands into the input file or they change the document's contents a little. This is a time consuming and tedious task. Manual intervention should be minimized.
In this thesis we propose a new measure of pagination quality that also allows a polynomial time pagination algorithm. Moreover, it results in paginations where a reader is not unnecessarily often interrupted during reading the document. At the Electronic Publishing Conference EP'96 [BKKW96] we have introduced this measure and have presented the first practical results.
In this thesis we also measure the quality of paginations produced by today's formatting systems according to our proposed measure. Today's formatting systems like LaTeX use a simple first-fit algorithm that belongs to the class of online algorithms. We use competitive analysis to show that any online pagination algorithm may produce arbitrarily bad results. This explains why so many people are not satisfied with paginations produced by LaTeX if no manual improvement is done.
To find optimal paginations (according to our measure of quality) more sophisticated algorithms are necessary. We show that a pagination algorithm based on dynamic programming is able to optimize our proposed measure.
We have implemented a prototype pagination program to prove that our proposed measure really leads to good paginations. Moreover, we want to integrate other aspects into the pagination algorithm, too. As already said, none of today's systems allows, for example, to specify that two figures should not be placed on the same page-spread.
Our pagination program allows to impose such additional constraints to the pagination task. The program searches for a pagination that satisfies all constraints and optimizes our measure of quality. Sometimes a user is not sure about which constraints are necessary. For this reason we have implemented a graphical user interface where an overview of a computed pagination is displayed. The user may interactively specify additional constraints and rerun the pagination procedure.
A precondition of interactive usage is a fast pagination procedure. If users have to wait too long for the pagination procedure to finish, nobody would want to interactively use the program. Therefore we have developed some techniques that produce a fast enough pagination procedure. To achieve the speed, different techniques have to be combined.
© Universität Bonn, Informatik Abt. I - webmaster - Letzte Änderung: Tue Oct 16 16:29:28 2001